
微积分(深度学习)
安装 matplotlib 库和 d2l 库
1 | conda activate d2l |
验证安装
1 | import matplotlib |
导数和微分
假设我们有一个函数$f: \mathbb{R} \rightarrow \mathbb{R}$,其输入和输出都是标量,如果$f$的导数存在,这个极限被定义为:
$$
f’(x) = \lim_{h \rightarrow 0} \frac{f(x+h) - f(x)}{h}.
$$
如果$f’(a)$存在,则称$f$在$a$处是可微(differentiable)的。
1 | %matplotlib inline |
%matplotlib inline:Jupyter Notebook 的 魔法命令,让matplotlib生成的图像直接嵌入在 Jupyter Notebook 的输出单元格中,而不是弹出一个单独的窗口from matplotlib_inline import backend_inline:确保图像在 Jupyter Notebook 中 直接显示,而不会单独弹出窗口from d2l import torch as d2l:从d2l(《动手学深度学习》的官方库)中 导入 PyTorch 版本的工具包,d2l封装了一些绘图、数据加载等功能,方便深度学习相关任务
1 | def numerical_lim(f, x, h): |
deff numerical_lim:定义导数h={h:.5f}:格式化h为小数点后 5 位numerical_lim(f, 1, h):.5f:计算f(x)在x=1处的导数,并格式化输出
等价符号
给定$y=f(x)$,其中$x$和$y$分别是函数$f$的自变量和因变量。以下表达式是等价的:
$$
f’(x) = y’ = \frac{dy}{dx} = \frac{df}{dx} = \frac{d}{dx} f(x) = Df(x) = D_x f(x)
$$
可视化
为了对导数的这种解释进行可视化,我们将使用matplotlib
use_svg_dieplay()
use_svg_display函数指定matplotlib软件包输出svg图表以获得更清晰的图像
1 | def use_svg_display(): #@save |
backend_inline:matplotlib_inline库中的模块,用于控制 Jupyter Notebook 内嵌 Matplotlib 图像的显示格式set_matplotlib_formats('svg'):设置 Matplotlib 生成的图像格式为 SVG(可缩放矢量图):- SVG(Scalable Vector Graphics) 是一种矢量图格式,放大后不会模糊,适合高分辨率显示(比如 Retina 屏幕)
- 默认 Matplotlib 使用 PNG 格式,但 PNG 是像素图,放大会变模糊,而 SVG 保持清晰
#@save:d2l库(《动手学深度学习》)的特殊标记:在d2l代码工具中自动保存这个函数,以便在后续 Notebook 运行时可以直接调用,而不需要重新定义
set_figsize()
定义set_figsize函数设置图表大小。
注意,这里可以直接使用d2l.plt,因为导入语句 from matplotlib import pyplot as plt已标记为保存到d2l包中
1 | def set_figsize(figsize=(3.5, 2.5)): #@save |
def set_figsize(figsize=(3.5, 2.5)):定义一个函数set_figsize(),默认图像大小为 (3.5, 2.5) 英寸(宽 3.5 英寸,高 2.5 英寸)figsize是一个 可选参数,允许用户自定义图像大小
use_svg_display():确保 所有 Matplotlib 图像都以 SVG 格式显示figure.figsize:控制 默认的 Matplotlib 图像尺寸,单位是 英寸(inch)d2l.plt.rcParams['figure.figsize'] = figsize:修改 Matplotlib 所有后续图像的默认大小(用户 不需要每次手动设置figsize,直接plt.plot()画图时就会应用这个默认尺寸)
set_axes()
set_axes函数用于设置自定义 Matplotlib 图表的坐标轴,包括:
轴标签 (
xlabel,ylabel)坐标轴范围 (
xlim,ylim)坐标轴比例 (
xscale,yscale)图例 (
legend)网格 (
grid())
1 | #@save |
axes.set_xlabel(xlabel)&axes.set_ylabel(ylabel)分别 设置 x 轴和 y 轴的标签,用于描述数据含义
axes.set_xscale(xscale)&axes.set_yscale(yscale)设置坐标轴的比例(scale):
linear(线性比例,默认)log(对数比例,适用于数据跨度较大的情况)
axes.set_xlim(xlim)&axes.set_ylim(ylim)设置 x 轴和 y 轴的显示范围(xlim=(0, 10)
表示 x 轴范围为[0, 10])axes.legend(legend):如果
legend不为空,则添加图例(legend=["fro曲线1", "曲线2"],就会在图中显示这些曲线名称)axes.grid():显示网格
plot()
通过这三个用于图形配置的函数,定义一个plot函数来简洁地绘制多条曲线
1 | #@save |
代码参数
| 参数 | 作用 |
|---|---|
X |
横坐标数据,可以是一维数组或多条曲线的 x 轴数据 |
Y |
纵坐标数据,可以是一维数组或多条曲线的 y 轴数据 |
xlabel / ylabel |
x 轴 / y 轴的标签 |
legend |
图例(legend),用于标注不同曲线 |
xlim / ylim |
x 轴 / y 轴的范围(比如 (0,10)) |
xscale / yscale |
坐标轴的比例(默认为 linear,可以改为 log) |
fmts |
曲线样式,默认支持 - (实线),m-- (紫色虚线),g-. (绿色点划线),r: (红色点线) |
figsize |
绘图尺寸(默认 (3.5, 2.5)) |
axes |
指定 Matplotlib 轴对象,如果为 None,则使用当前轴 |
设置图像大小
set_figsize():
获取 Matplotlib 轴对象
axes = axes if axes else d2l.plt.gca():如果 axes 参数 为空,则调用 d2l.plt.gca() 获取当前轴对象(Matplotlib 的 gca() 返回当前的 axes)
检查 X 是否为一维数组
def has_one_axis(X):检查 X 是否为一维数组
hasattr(X, "ndim") and X.ndim == 1:检查X是否是 NumPy 数组,并且是一维的isinstance(X, list) and not hasattr(X[0], "__len__"):检查X是否是 Python 列表,并且列表中的 元素不是列表(即X是一维列表)
代码拆解:
hasattr(X, "ndim"):hasattr是一个 Python 内置函数,用于检查对象是否有某个属性。这里检查的是X是否有ndim属性(通常是numpy数组才会有ndim属性,它表示数组的维度)。X.ndim == 1:这检查X是否是一维数组。X.ndim表示数组的维度。isinstance(X, list):这检查X是否是一个 Pythonlist类型(即普通列表)not hasattr(X[0], "__len__"):这检查X中的第一个元素(X[0])是否没有__len__属性。__len__属性通常用于表示对象的长度(例如列表)。如果X[0]不是列表或其他可迭代对象,就说明X是一个一维的普通列表,而不是嵌套列表
处理X和Y数据
1 | if has_one_axis(X): |
如果
X是 一维数据,转换为 二维列表(X = [X]),这样可以绘制多条曲线如果 没有提供
Y,则X变为空列表,Y = X(支持plot(Y)的情况)实际意义:如果
Y为空,则假定X实际上是Y,并自动生成X,Matplotlib 会自动使用索引[0,1,2,...]作为X如果
Y是 一维数据,转换为 二维列表(Y = [Y])如果
X和Y长度不匹配,复制X以匹配Y的长度(适用于X只有一组数据,而Y有多组)
example:
1 | X = [1, 2, 3] |
1 | X = [1, 2, 3] |
1 | Y = [2, 4, 6] |
1 | X = [[1, 2, 3]] # 只有一个 X |
绘制曲线
1 | axes.cla() # 清除当前轴的内容 |
axes.cla()清除当前坐标轴的内容,避免重复绘制。zip(X, Y, fmts)逐一取出
x, y, fmt:axes.plot(x, y, fmt)画曲线(fmt指定曲线样式)。- 如果
x为空,则直接绘制y,Matplotlib 默认x = range(len(y))。
设置坐标轴
set_axes(axes, xlabel, ylabel, xlim, ylim, xscale, yscale, legend):统一设置坐标轴参数(坐标范围、刻度、比例、标签等)
例子
1 | x = np.arange(0, 3, 0.1) |
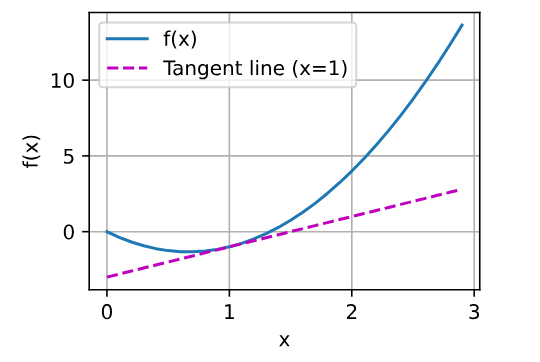
偏导数
将微分的思想推广到多元函数(multivariate function)上
设$y = f(x_1, x_2, \ldots, x_n)$是一个具有$n$个变量的函数,$y$关于第$i$个参数$x_i$的偏导数(partial derivative)为:
$$
\frac{\partial y}{\partial x_i} = \lim_{h \rightarrow 0} \frac{f(x_1, \ldots, x_{i-1}, x_i+h, x_{i+1}, \ldots, x_n) - f(x_1, \ldots, x_i, \ldots, x_n)}{h}.
$$
等价符号
对于偏导数的表示,以下是等价的:
$$
\frac{\partial y}{\partial x_i} = \frac{\partial f}{\partial x_i} = f_{x_i} = f_i = D_i f = D_{x_i} f.
$$
梯度
连结一个多元函数对其所有变量的偏导数,以得到该函数的梯度(gradient)向量
设函数$f:\mathbb{R}^n\rightarrow\mathbb{R}$的输入是一个$n$维向量$\mathbf{x}=[x_1,x_2,\ldots,x_n]^\top$,并且输出是一个标量,函数$f(\mathbf{x})$相对于$\mathbf{x}$的梯度是一个包含$n$个偏导数的向量:
$$
\nabla_{\mathbf{x}} f(\mathbf{x}) = \bigg[\frac{\partial f(\mathbf{x})}{\partial x_1}, \frac{\partial f(\mathbf{x})}{\partial x_2}, \ldots, \frac{\partial f(\mathbf{x})}{\partial x_n}\bigg]^\top
$$
其中$\nabla_{\mathbf{x}} f(\mathbf{x})$通常在没有歧义时被$\nabla f(\mathbf{x})$取代
常用结论
假设$\mathbf{x}$为$n$维向量,在微分多元函数时经常使用以下规则:
- 对于所有$\mathbf{A} \in \mathbb{R}^{m \times n}$,都有$\nabla_{\mathbf{x}} \mathbf{A} \mathbf{x} = \mathbf{A}^\top$
- 对于所有$\mathbf{A} \in \mathbb{R}^{n \times m}$,都有$\nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{A} = \mathbf{A}$
- 对于所有$\mathbf{A} \in \mathbb{R}^{n \times n}$,都有$\nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{A} \mathbf{x} = (\mathbf{A} + \mathbf{A}^\top)\mathbf{x}$
- $\nabla_{\mathbf{x}} |\mathbf{x} |^2 = \nabla_{\mathbf{x}} \mathbf{x}^\top \mathbf{x} = 2\mathbf{x}$
同样,对于任何矩阵$\mathbf{X}$,都有$\nabla_{\mathbf{X}} |\mathbf{X} |_F^2 = 2\mathbf{X}$
链式法则
在深度学习中,多元函数通常是复合(composite)的, 所以难以应用上述任何规则来微分这些函数。幸运的是,链式法则可以被用来微分复合函数。
单变量函数
让我们先考虑单变量函数。假设函数$y=f(u)$和$u=g(x)$都是可微的,根据链式法则:
$$
\frac{dy}{dx} = \frac{dy}{du} \frac{du}{dx}.
$$
任意数量的变量
假设可微分函数$y$有变量$u_1, u_2, \ldots, u_m$,其中每个可微分函数$u_i$都有变量$x_1, x_2, \ldots, x_n$。注意,$y$是$x_1, x_2, \ldots, x_n$的函数。对于任意$i = 1, 2, \ldots, n$,链式法则给出:
$$
\frac{\partial y}{\partial x_i} = \frac{\partial y}{\partial u_1} \frac{\partial u_1}{\partial x_i} + \frac{\partial y}{\partial u_2} \frac{\partial u_2}{\partial x_i} + \cdots + \frac{\partial y}{\partial u_m} \frac{\partial u_m}{\partial x_i}
$$
自动微分
例子
对函数$y=2\mathbf{x}^{\top}\mathbf{x}$关于列向量$\mathbf{x}$求导
1 | import torch |
requires_grad_(True): 使x具有 自动求导 功能(梯度计算)x.grad:默认是None,因为梯度只有在backward()调用后才会被计算y.backward():y对x进行反向传播,计算梯度dy/dxgrad_fn=<MulBackward0>:grad_fn(Gradient Function)是 PyTorch 自动求导机制 (autograd) 记录的 计算历史,它指向了 生成这个张量的运算,从而支持反向传播MulBackward0代表乘法的反向传播(Backward代表反向传播)
x的另一个函数
1 | # 在默认情况下,PyTorch会累积梯度,我们需要清除之前的值 |
非标量变量的反向传播
1 | # 对非标量调用backward需要传入一个gradient参数,该参数指定微分函数关于self的梯度。 |
x.grad.zero_():清空x.grad。在 PyTorch 中,backward()不会自动清空x.grad,如果不手动清除,梯度会 累积
注意:
在 PyTorch 中,backward() 的默认行为是 计算 y 对 x 的梯度,并存入 x.grad。但 backward() 只能对 标量(单个数值)调用,如果 y 是 张量(向量/矩阵),就必须手动指定如何计算梯度。
y类型 |
直接.backward() |
需要y.sum()吗 |
解决方案 |
|---|---|---|---|
标量:shape=() |
✔允许 | ✗不需要 | y.backward() |
向量:shape=(n,) |
✗报错 | ✔需要 | y.sum()或y.backward(torch.ones_like(y)) |
矩阵:shape=(m,n) |
✗报错 | ✔需要 | y.sum()或y.backward(torch.ones_like(y)) |
分离计算
有时,我们希望将某些计算移动到记录的计算图之外。
例如,假设y是作为x的函数计算的,而z则是作为y和x的函数计算的。我们想计算z关于x的梯度,但由于某种原因,希望将y视为一个常数,并且只考虑到x在y被计算后发挥的作用。
这里可以分离y来返回一个新变量u,该变量与y具有相同的值,但丢弃计算图中如何计算y的任何信息。换句话说,梯度不会向后流经u到x。因此,下面的反向传播函数计算z=u*x关于x的偏导数,同时将u作为常数处理,而不是z=x*x*x关于x的偏导数。
1 | x.grad.zero_() |
detach():返回一个与y具有相同值的新张量u,但不参与梯度计算。u不会计算梯度,也不会影响x.grad
随后在y上调用反向传播
1 | x.grad.zero_() |
Python控制流的梯度计算
1 | def f(a): |
torch.randn(size=())生成一个 零维(标量) 的随机数a,其值服从 标准正态分布requires_grad=True使a参与自动求导
其他
为什么计算二阶导数比一阶导数的开销要更大?
- 计算图更复杂
- 需要存储更多的中间变量
- 计算二阶导数需要两次反向传播
在运行反向传播函数之后,立即再次运行它,看看会发生什么?
如果在没有设置 retain_graph=True 的情况下,立即再次运行 backward(),PyTorch 会报错:
1 | x = torch.tensor(2.0, requires_grad=True) |
为什么会报错
当 backward() 运行时,PyTorch 默认会释放计算图,以节省内存。因此:
- 第一次调用
y.backward():- PyTorch 计算
dy/dx并存储在x.grad里。 - 计算完成后,PyTorch 释放计算图,清除所有用于计算梯度的中间变量。
- PyTorch 计算
- 第二次调用
y.backward():- 由于计算图已经释放,PyTorch 无法再次计算梯度,因此报错。
如何避免这个问题
如果你想在 同一个计算图上多次调用 backward(),需要在第一次 backward() 时 保留计算图:
1 | y.backward(retain_graph=True) # 允许计算图保留 |
什么时候需要多次 backward()?
- 计算二阶导数(如 Hessian 矩阵)
- 多次计算梯度(如在强化学习中的策略梯度方法)
但一般情况下,只需要一次 backward() 即可,无需 retain_graph=True
使$f(x)=\sin(x)$,绘制$f(x)$和$\frac{df(x)}{dx}$的图像,其中后者不使用$f’(x)=\cos(x)$
1 | %matplotlib inline |
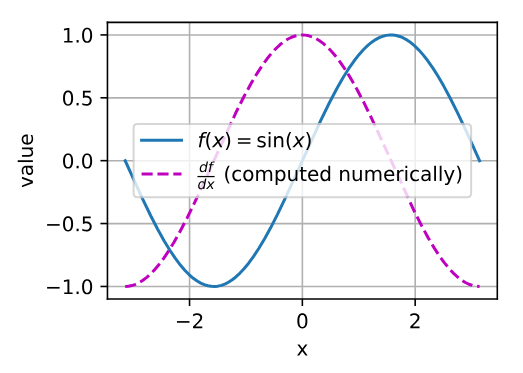
注意点
将 x、y 和 dy_dx 转换为 NumPy 数组 时,使用 .detach().numpy():
1 | d2l.plot(x.detach().numpy(), [y.detach().numpy(), dy_dx.detach().numpy()], 'x', 'value', legend=[r'$f(x) = \sin(x)$', r"$\frac{df}{dx}$ (computed numerically)"]) |
原因
在 PyTorch 中:
tensor.numpy()不能用于requires_grad=True的张量- 需要先调用
tensor.detach(),这样 PyTorch 就不会追踪计算图,可以安全地转换为 NumPy
原理
**Pytorch 计算图与自动求导:**在 PyTorch 中,每当你对一个 requires_grad=True 的张量执行操作,PyTorch 会构建一张计算图,用于追踪所有计算,以便稍后进行 反向传播(backpropagation)。
**为什么 numpy() 不允许直接调用?:**当 requires_grad=True 时,直接调用 .numpy() 会破坏计算图,这会导致 PyTorch 无法继续反向传播。
如何解决?:detach() 方法的作用是 从计算图中分离张量,使其成为普通张量,不再追踪梯度。因此,我们可以先 detach() 再 numpy()










